Importing USDA Census of Agriculture Data into R
Post-Thanksgiving, America is experiencing a different kind of hunger – a hunger for agricultural data that is easy to process in the programming language R.
24 November 2017

Finding Data
The USDA Census of Agriculture (or “Ag Census”) is an incredible source of pretty much any kind of agricultural data that you might be looking for, and I’ve used this census in two previous posts. In those posts, I copied and pasted relevant information from a .pdf file. This was fine because I wasn’t working with that much data, but this definitely wouldn’t work if I were doing something bigger, like looking at factory farms by county.
Browsing through the Ag Census site, there seems to be no clear way to get all of the census information at once. There are .pdf files and .txt files with information and tables, but none of those are easily importable. There is also a Quick Stats database with this information, which you can query on the website or through an API. This was more promising but still wasn’t not quite what I was looking for. I wanted all of the raw data, without any processing done. Then I noticed a link at the bottom of the API page, which lead to all the raw Ag Census data in tabular format. This was exactly what I was looking for.
Importing Data
After finding the data, I wrote an R script that downloads all Ag Census data from the internet, converts it to R, and saves it in a folder.
#download, convert, import US Census of Agriculture Data into R
#set up
dir.create("raw")
dir.create("rImported")
#all files from USDA FTP quickstats site ftp://ftp.nass.usda.gov/quickstats/
#best way for of downloadable tabular census data I know of
#download to censusData
setwd("raw")
download.file("ftp://ftp.nass.usda.gov/quickstats/qs.census2002.txt.gz", "2002.txt.gz")
download.file("ftp://ftp.nass.usda.gov/quickstats/qs.census2007.txt.gz", "2007.txt.gz")
download.file("ftp://ftp.nass.usda.gov/quickstats/qs.census2012.txt.gz", "2012.txt.gz")
#convert to r
cag2002 <- read.table(gzfile("2002.txt.gz"), sep="\t", header=TRUE)
cag2007 <- read.table(gzfile("2007.txt.gz"), sep="\t", header=TRUE)
cag2012 <- read.table(gzfile("2012.txt.gz"), sep="\t", header=TRUE)
#save
setwd("../rImported")
save(cag2002,file="cag2002.Rda")
save(cag2007,file="cag2007.Rda")
save(cag2012,file="cag2012.Rda")
Here’s what this looks like imported (in RStudio):
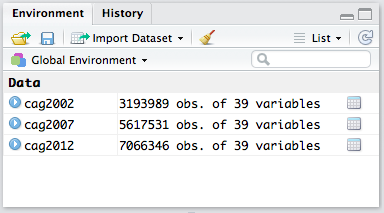
In R: Ag Census data by year
Now I have a many millions of instances of data that spans across 3 different years to work with. Variable names are listed in the Quick Stats API documentation. I’m also ready as soon as the 2017 Ag Census comes out, which is soon. When I work with this data in the future, I will be able to analyze it in a pipeline: everything I post will be immediately reproducible by anyone else, and there won’t be any room for potential copy-paste errors!
As always, this code is on GitHub. The data files themselves are too large to be uploaded there (> 25 mb).
24 november 2017. cross-posted on steemit and my site. filed under agriculture, statistics, and R.